
第1节,使用openpyxl 读取excel文件
本系列所有代码和示例文件均可以下载,关注右侧公众号,回复: excel 即可获得下载链接
使用python对excel进行自动化操作,我推荐使用openpyxl,因为它同时支持读写excel,而流行的xlrd 只支持读操作而xlwt 只支持写操作。
实现对excel的读取,只需要以下几个轻松的步骤
1. 引入openpyxl
from openpyxl import load_workbook
2. 打开excel文件
file_path = './求一行数据的和.xlsx'
workbook = load_workbook(file_path)
使用load_workbook函数打开excel文件,获得整个excel对象
3. 选取sheet
一个excel 有一个或多个sheet, 使用python读取excel数据时,必须指定要读取哪个sheet的数据
sheet = workbook.get_sheet_by_name('学生成绩')
get_sheet_by_name 方法允许你根据sheet名称获取sheet对象,在你使用python读取excel之前,你应当已经了解excel里的内容,比如有多少个sheet, sheet的名称,数据存储在哪一行哪一列,如果这些您都不知道,那么自动化将无法实现,一言以蔽之,你不知道该怎样做的事情,程序也不会知道。
get_sheet_names方法可以返回excel里所有的sheet名称。
4. 读取sheet中的数据
4.1 获取行列信息
在读取sheet的数据时,你应当首先获取这个sheet页的数据有多少行,多少列,得到这些信息后就可以按行遍历或者是按列进行遍历。
start_row = sheet.min_row # 起始行
end_row = sheet.max_row # 结束行
start_col = sheet.min_column # 起始列
end_col = sheet.max_column # 结束列
print(start_row, end_row, start_col, end_col)
openoyxl 会自动帮你识别数据的行列范围,以下图数据为例
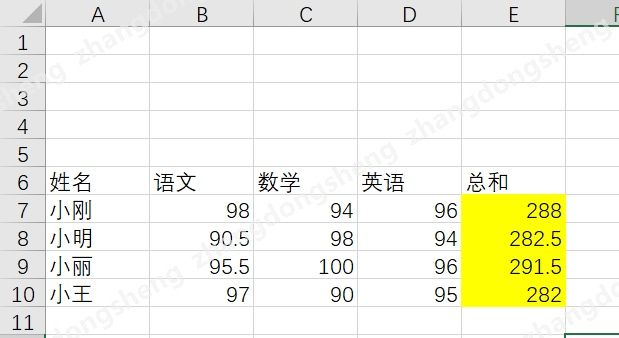
数据的起始行并不是1, 而是6, 从第6行开始才开始有数据,数据的起始列是1, 也就是A这一列。openpyxl 所有涉及到索引的操作都是从1开始的,这样做违背了编程语言普遍遵守的索引从0开始的原则,但有助于非计算机从业人员使用它操作excel, 因为excel里行的索引是从1开始的,人们在编程时可以不经过换算使用从excel里获得索引数值。
4.2 读取某个单元格
读取一个单元格的数据,需要指定单元格的行号与列号,以下图数据为例
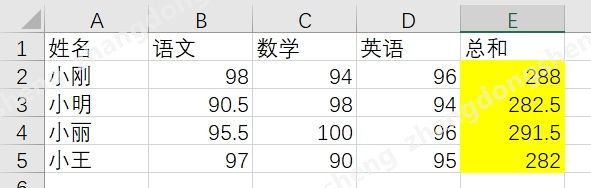
读取小刚的考试分数总和,需要读取第2行第5列的单元格的数据
score_sum = sheet.cell(2, 5)
print(score_sum, type(score_sum)) # <Cell '学生成绩'.E2> <class 'openpyxl.cell.cell.Cell'>
cell方法的返回值是Cell类型,但我们其实只希望获取单元格里的值,Cell类型数据通常对我们没有什么帮助,单元格的值存储在value属性里
score_sum = sheet.cell(2, 5).value
print(score_sum, type(score_sum)) # 288 <class 'int'>
openpyxl 会尝试帮你推断数据的类型,它会尽可能将数据类型转换为int或者float。
处理使用cell方法,你还可以单元格的名称来获取数值,这种方式很适合读取指定位置的单元格数据
print(sheet['E2'].value)
4.3 按行遍历
按行遍历数据,可使用iter_rows方法
def iter_rows(self, min_row=None, max_row=None, min_col=None, max_col=None, values_only=False):
pass
该方法允许你指定遍历开始和结束的行,同时可以指定这些行数据在列上起始和结束位置,设置这4个参数,可以获取指定大小的矩形范围内的数据,如果这些参数都不指定,那么就全量遍历,等同于调用rows方法,rows方法在内部调用iter_rows方法。
for row in sheet.rows:
print(row)
row 的类型是元组,元组里的元素都是Cell类型,想要获得单元格的存储内容,还需要你进一步做处理
rows = []
for row in sheet.rows:
rows.append([cell.value for cell in row])
print(rows)
我很奇怪,为什么openpyxl不提供更直接一点的方法让用户直接获得单元格的实际存储值呢,非要返回Cell对象,让人不得不进一步做处理,如果不是因为它能同时支持读和写,我真不想使用它。
4.4 按列遍历
与按行遍历相似,openpyxl提供了iter_cols 和 columns方法,使用方法参考4.3
cols = []
for col in sheet.columns:
cols.append([cell.value for cell in col])
print(cols)
4.5 读取某一行或者某一列的数据
想要读取某一行数据,那么你一定是事先知晓了行号,假设要读取第一行的内容
row = sheet.iter_cols(min_col=start_col, max_col=end_col, min_row=1, max_row=1)
row = [cell[0].value for cell in row]
print(row) # ['姓名', '语文', '数学', '英语', '总和']
还有更简单点的写法
row = []
for i in range(start_col, end_col+1):
row.append(sheet.cell(1, i).value)
print(row) # ['姓名', '语文', '数学', '英语', '总和']
获取第一列的数据,可以这样写
col = []
for i in range(start_row, end_row + 1):
col.append(sheet.cell(i, 1).value)
print(col) # ['姓名', '小刚', '小明', '小丽', '小王']

扫描关注, 与我技术互动
QQ交流群: 211426309
