
正则表达式之特殊代码
python正则表达式中,特殊代码匹配一类字符, .匹配除换行符以外的任意字符, \w匹配字母或数字, \s匹配任意的空白符, \d匹配数字, \b匹配单词的开始或结束, ^匹配字符串的开始, $匹配字符串的结束
上一篇教程中,你接触了一个简单的正则表达式book,并使用它在目标字符串中进行了匹配,如果足够细心,你可能会注意到,在字符串"this is a book"中,有两个is,如果正则表达式is去匹配,结果会是怎样呢?
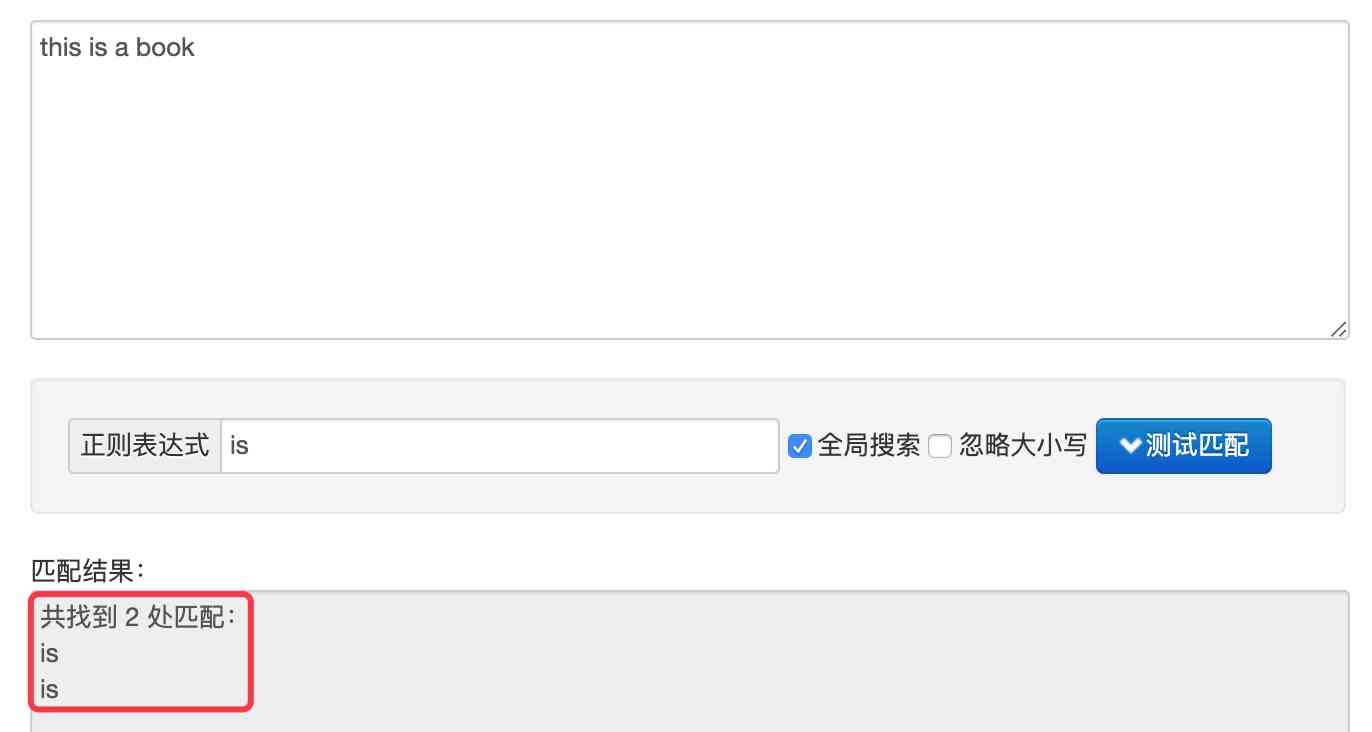
和预期的一致,找到了两个is,但是这样就有了问题,如果只想找到单词is,不想找到其他单词中包含的is,该怎么写正则表达式呢?
你应该这样写正则表达式: \bis\b ,\b匹配单词的开始或者结束,如此一来,就可以准确的匹配到单词is了。
在正则表达式中\b 是特殊字符,特殊字符有着特殊的作用,他们被用来代表某些特定的字符。
| 代码/语法 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
接下来逐一讲解这些特殊字符
1. 匹配除换行符以外的任意字符
. 用来匹配除了换行符意外的其他任意字符,这个和sql语句中的通配符是相同的作用。
假设目标字符串是 "like and love",现在,我想找符合以下条件的单词
- 单词长度是4
- 单词首字母是l
- 单词末尾字母是e
好,根据这个规则,我写出正则表达式
\bl..e\b
- 前后各写一个\b, 就表示查找单词
- 以b开头,以e结尾
- 中间两个. 表示2个除回车符意外的任意字符
符合条件的单词有like 和 love
2. \w 匹配字母或数字
\w 只能匹配字母或者数字,相比于. 范围小了很多,但这样就可以用于更加精确的匹配
假设目标字符串是 "this is a book",现在,我想找到长度为4的单词,只要长度符合要求就可以了,那么正则表达式就可以这样写
\b\w\w\w\w\b
4个\w表示4个字母或数字,可以匹配的单词有 this 和 book
3. \s 匹配任意的空白符
空白符包括空格,制表符(tab),换行符这三个很特殊的字符,假设目标字符串是
I have a dream
现在想要匹配a dream 这一部分,就可以这样写正则表达式
a\sdream
4. \d 匹配数字
\d 只用来匹配数字,0到9的数字,假设目标字符串是
my phone number is 15801121234
现在,我想匹配字符串中的电话号,就可以这样写正则表达式
\d\d\d\d\d\d\d\d\d\d\d
这样刚好可以匹配到15801121234
5. ^ 和 $ 匹配字符串开始和结束
假设目标字符串是
this is a book
现在,只想验证字符串是不是以this开头,那么就可以这样来写正则
^this
如果可以匹配出结果,就说明字符串是以this开头的,同理,你可以用book$来验证字符串是以book结尾的。
6. 总结
特殊字符被用来表示特定的字符,通过上面的例子,你应该已经发现一些特殊字符的不足之处,以\d 所举的例子来说,为了表示一个电话号,竟然用了11个\d,这样写起来是不是太费力了,有没有什么别的规则,可以让特殊字符的数量更加灵活一些?
当然是有的,下一篇教程将教你如何控制字符的数量

扫描关注, 与我技术互动
QQ交流群: 211426309
