
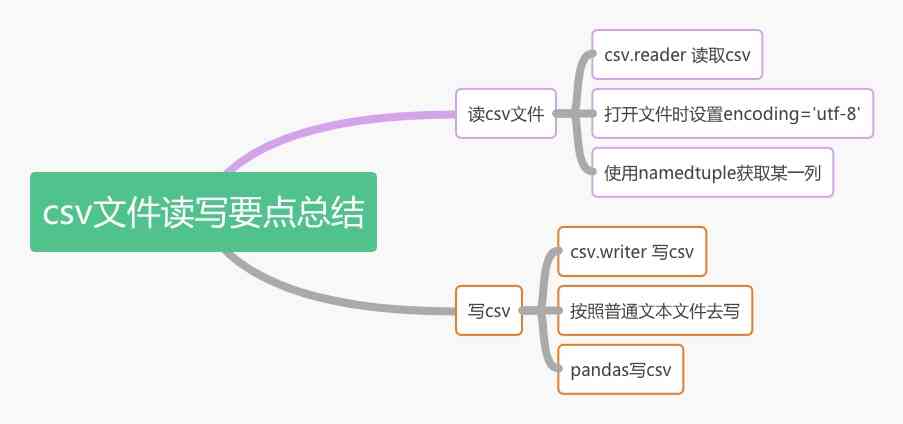
读取csv文件
csv是一种文本文件,因此python可以像读取文本文件一样读取csv文件,但通常我们使用专门的csv模块来读取csv文件,操作起来会更加的便利。
1. 读取csv文件
准备数据data.csv
name,age
小明,14
小刚,15
通常,我们用下面的代码读取csv
import csv
with open(r'C:\Users\zhangdongsheng\Desktop\data.csv', encoding='utf-8')as f:
reader = csv.reader(f)
headers = next(reader)
print(headers)
for row in reader:
print(row)
程序输出结果
['name', 'age']
['小明', '14']
['小刚', '15']
我们完全可以像读取txt文件那样去读取csv文件,但那样读取到的数据一行就是一个字符串,还需你自己进行一次split操作才能将数据分隔开,因此我建议你使用csv模块读取csv文件。
上面的读取方法,有一个让人感到难受的地方,每一行数据虽然都是以列表的形式返回,可如果你想获取一行中的某一列数据,就只能通过列表的索引,这样并不方便。
针对这个需求,可以使用namedtuple
import csv
from collections import namedtuple
with open(r'C:\Users\zhangdongsheng\Desktop\data.csv', encoding='utf-8')as f:
reader = csv.reader(f)
headers = next(reader)
Row = namedtuple('Row', headers)
for row in reader:
row = Row(*row)
print(row.name, row.age)
这样可以非常方便的获取一行数据中的某一列数据。
2. 写csv文件
2.1 普通方法写csv文件
用csv模块写csv文件,主要用到writerow和writerows这两个方法,前者是写入一行,后者是写入多行。
import csv
headers = ['name', 'age']
row_1 = ['小明', '14']
row_2 = ['小刚', '15']
with open("data.csv", "w", encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows([row_1, row_2])
在打开文件时,一定要设置encoding='utf-8' 否则中文无法正常显示,另外要设置newline='',否则就会在两行数据之间间隔一个空行。
csv文件是文本文件,因此你完全可以抛开csv模块,单纯的用写文本文件的方法来写csv文件
headers = ['name', 'age']
row_1 = ['小明', '14']
row_2 = ['小刚', '15']
with open("data.csv", "w", encoding='utf-8') as csvfile:
csvfile.write(','.join(headers) + "\n")
csvfile.write(','.join(row_1) + "\n")
csvfile.write(','.join(row_2))
2.2 用pandas写csv文件
使用pandas写csv文件需要先创建dataframe对象
import pandas as pd
headers = ['name', 'age']
row_1 = ['小明', '14']
row_2 = ['小刚', '15']
df = pd.DataFrame([row_1, row_2], columns=headers)
df.to_csv("data.csv", index=False, sep=',')
效果与csv模块写文件是一样的

扫描关注, 与我技术互动
QQ交流群: 211426309
