
掌握hashtable,深度理解python字典的数据结构
字典在python中几乎无处不在,它性能强劲,而且可靠,这源于底层的数据结构---hashtable。本文将向你介绍hashtable这种数据结构,你将学习掌握到以下知识点:
- hash函数
- hashtable数据结构
- python字典顺序写入
1. hash函数
在学习hashtable之前,首先需要掌握hash函数,你可能对hash函数并不了解,但你只要在使用计算机,就无时无刻不在使用它。你在网站上注册用户,密码不会明文保存,而是经过hash函数处理的密码,典型的有MD5。你在下载文件时,还会得到一个专门用来验证文件是否被串改的签名,这个签名是hash函数生成的。
hash函数是一个统称,有许多种实现算法,例如MD5、SHA-1、SHA-2、NTLM等等。
哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法,这是维基百科上的定义,换一种更容易理解的定义,哈希函数将任意长度的数据映射到固定长度的值。
哈希函数,有以下3个基本特性:
- 速度必须快,因为hash应用太广泛了,太基础了,速度慢是不可接受的
- 映射的结果是确定的,同一个原始输入,经hash函数处理后得到的散列值必须相同,如果两个散列值不同,那么他们的原始输入也不相同
- hash函数产生固定长度的值,这里的固定长度指的是存储散列值所占用的字节数相同
除了上面的3个基本特性,还有一个比较常见的特性,hash过程是不可逆的,这便是说,即便给了你散列值,你也无法逆向算出原始输入,在密码学里,这一点是必须保证的。由于hash函数产生的散列值的长度是固定的,这意味着散列值的个数是有限的,而原始输入却可以是无限多个,因此,两个不同的输入,可能会得到一个相同的散列值,这个叫散列碰撞(collision),散列碰撞是无法避免的,好的hash算法只能是降低碰撞的概率,而无法杜绝。
python的内置函数hash就是一个hash函数,它可以计算任意不可变对象的hash值
>>> hash('323')
-2887333350099739771
>>> hash(323)
323
>>> hash(4334.2323)
535647331039580398
>>> hash((1, 3))
3713081631933328131
hash函数返回的是int类型数据,前面已经强调过,hash函数返回固定长度的值,这里的固定长度,指的是存储这个值所用的字节数,虽然这些int类型的数值大小不同,看起来长度不一致,但存储他们所用的字节数是相同的。对于自定义类,可以重写魔法方法__hash__来实现自己的hash函数。
对于可变对象,例如列表,是不能被hash的
>>> hash([1, 2, 3])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
2. hashtable
2.1 链地址法实现hashtable
hashtable是一种可以存储键值对的数据结果。
hashtable的实现基础是数组,数组这种数据结构在内存层面是,是一片连续的空间,通过索引来存储和读取数据,效率自然是高。python里没有数组,因此,我用列表来实现一个hastable。
class PyHashTable():
def __init__(self, datas=None):
if datas is None:
self.length = 8
else:
self.length = len(datas)
self.buckets = [[] for i in range(self.length)]
self.init_buckets(datas)
def init_buckets(self, datas):
if datas is None:
return
for key, value in datas:
self.__setitem__(key, value)
def __getitem__(self, search_key):
hash_value = abs(hash(search_key))
index = hash_value % self.length
for key, value in self.buckets[index]:
if search_key == key:
return value
def __setitem__(self, key, value):
hash_value = abs(hash(key))
index = hash_value % self.length
self.buckets[index].append((key, value))
datas = [('python', 90), ('java', 98), ('php', 85), ('c', 100)]
hashtable = PyHashTable(datas)
print(hashtable['c']) # 像使用字典一样
hashtable['c++'] = 92
print(hashtable['c++'])
print(hashtable.buckets)
程序输出结果
100
92
[
[],
[('python', 90), ('c++', 92)],
[('java', 98), ('c', 100)],
[('php', 85)]]
PyHashTable,并不是一个完整的实现,一些功能并没有添加,比如删除某个key,但已经将hashtable最核心的结构和操作体现出来了,写入新的key-value对,通过key获取value,操作方式和字典是一样的。
2.2 解决冲突
在实现hashtable时,需要解决冲突,毕竟buckets不是无限大的,python和c++经过hash后的散列值虽然不同,但是对self.length取模后是相同的,这导致他们两个被放到了同一个桶里。
hashtable解决冲突的方法常见的有两种:
- 开放寻址
- 链地址法
我刚才的实现,其实就算是链地址法,冲突的key被放到了同一个桶里,而这个桶使用列表来存储冲突的key, 我也可以不用列表,而是改成链表来存储这些冲突的key-value对,不过实现链表又需要好多代码,因此这里换成列表,其算法思路是一致的。
开放寻址的思路是这样的,还是先根据key,算出来应当放在哪个桶里,如果这个桶里面已经有key-value对了,那么就向后移动一个位置,直到找到一个空的桶。
在思考这个算法时,你可能会担心这种情况的发生,一个key(key_1)原本应当被放在n号桶里,但是n号桶里已经有值了,此时产生冲突,采用开发寻址方案,向下寻找空桶,结果找到了n + k号空桶,于是将这个key1-value对放入其中。这之后产生了两个担忧:
- 新写入一个key2-value, kye2恰好被分配到n + k号,而此时n + k号桶被key1占据了,key2只好向下寻找空桶。
- key1本应放到n号桶,而实际存放位置是n + k 号桶,根据key1查询value时,先到n号桶查询,n号桶里的key自然不等于key1, 于是继续向下寻找直到遇到一个空桶(表明key1不存在),key1在n + k号桶里,这样的寻找过程,要比较k次,如果大量的key都存在冲突,不论是写入还是查询,其性能都会有所下降。
- 开放寻址可以避免空间的浪费,但是不同于链地址法,当buckets被装满时,就找不到一个空的桶可以使用了,这个时候怎么办呢?
关于第一个担忧,是没有必要的,key2被迫向下寻找空桶,是开放寻址方案所允许的,也几乎是必然存在的情况。
2,3两个担忧,的确是个问题,但可以用同一个方法来解决,这个方法是扩容。python实现的hashtable,有2/3被装满时,就会进行扩容,扩容后,就不必担心没有空桶可用了,扩容也会减小k的数值,不至于出现性能下降。
2.3 开放寻址法实现hashtable
下面是使用开放寻址方案实现的hashtable, 我这里没有实现扩容
# program_dict = {
# 'python': 90,
# 'java': 98,
# 'php': 85,
# 'c': 100
# }
#
# print(program_dict)
class PyHashTable():
def __init__(self, datas=None):
if datas is None:
self.length = 8
else:
self.length = len(datas) * 2
self.buckets = [None for i in range(self.length)]
self.init_buckets(datas)
def init_buckets(self, datas):
if datas is None:
return
for key, value in datas:
self.__setitem__(key, value)
def __getitem__(self, search_key):
hash_value = abs(hash(search_key))
index = hash_value % self.length
while self.buckets[index] is not None:
if self.buckets[index][0] == search_key:
return self.buckets[index][1]
index = (index + 1) % self.length
return None
def __setitem__(self, key, value):
hash_value = abs(hash(key))
index = hash_value % self.length
while self.buckets[index] is not None:
index = (index + 1) % self.length
self.buckets[index] = (key, value)
datas = [('python', 90), ('java', 98), ('php', 85), ('c', 100)]
hashtable = PyHashTable(datas)
print(hashtable['c'])
hashtable['c++'] = 92
print(hashtable['c++'])
print(hashtable.buckets)
程序输出结果
100
92
[
('python', 90),
('java', 98),
None,
None,
None,
('php', 85),
('c', 100),
('c++', 92)
]
和第一版实现相比,改动有3处
第一处,初始化时,扩大buckets容量并且不再使用二维列表
def __init__(self, datas=None):
if datas is None:
self.length = 8
else:
self.length = len(datas) * 2
self.buckets = [None for i in range(self.length)]
第二处,写入key-value对时,开放寻址
def __setitem__(self, key, value):
hash_value = abs(hash(key))
index = hash_value % self.length
while self.buckets[index] is not None:
index = (index + 1) % self.length
self.buckets[index] = (key, value)
第三处,根据key查询value时,开放寻址
def __getitem__(self, search_key):
hash_value = abs(hash(search_key))
index = hash_value % self.length
while self.buckets[index] is not None:
if self.buckets[index][0] == search_key:
return self.buckets[index][1]
index = (index + 1) % self.length
return None
2.4 逻辑删除key
如果你想实现hashtable删除key的功能,那么要明白一点,key的删除只能是逻辑删除,而不能是物理删除,这里假设('python', 90) 和 ('java', 98)发生了冲突,java被迫开放寻址,放在了紧挨着python的一个桶里。接下来,物理删除('python', 90),将0号桶设置为None, 然后根据java来查询value,按照现在的算法,是找不到的,因为先找到了0号桶,可是0号桶里的值是None, 是一个空桶,while循环不会被执行。
解决冲突key删除的办法是采用逻辑删除,将桶里的值设置为一个可以标识该key已经删除的对象
class HasDeleted():
def __getitem__(self, item):
return None
class PyHashTable():
def __delitem__(self, del_key):
hash_value = abs(hash(del_key))
index = hash_value % self.length
while self.buckets[index] is not None:
if self.buckets[index][0] == del_key:
self.buckets[index] = HasDeleted()
return True
index = (index + 1) % self.length
return False
增加了__delitem__,逻辑删除一个key, 那么__setitem__方法也要做出修改,这个执行了逻辑删除的桶,应当被视为一个空的桶。
def __setitem__(self, key, value):
hash_value = abs(hash(key))
index = hash_value % self.length
while not isinstance(self.buckets[index], (type(None), HasDeleted)):
index = (index + 1) % self.length
self.buckets[index] = (key, value)
3. python的字典
从python3.6开始,字典被设计成顺序写入,这意味着字典保存了key-value对写入的顺序,在python2.7中执行下面的代码
program_dict = {
'python': 90,
'java': 98,
'php': 85,
'c': 100
}
print(program_dict)
程序输出结果
{
'python': 90,
'c': 100,
'php': 85,
'java': 98
}
输出时,key的顺序与创建时key的顺序是不同的,同样的代码在python3.6环境下执行,输出的结果是
{
'python': 90,
'java': 98,
'php': 85,
'c': 100
}
输出时,key的顺序与创建时key的顺序是相同的,这证明python的字典保存了key-value写入时的顺序。
在python3.6之前,python的字典用一个hashtable来存储key-vlaue, 3.6以后,用一个密集数组来存储key-value对,用一个稀疏数组存储key-value对的索引,两者结合实现了一个字典。
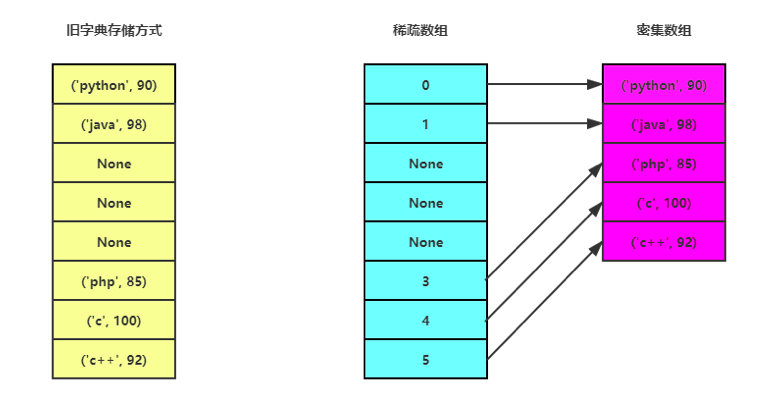
这样的数据结构,将使用更少的内存,提供更快的遍历速度,同时在遍历字典和转换为其他数据类型时可以保持其写入顺序。
在插入一个新的key-value对时,首先写入密集数组,获得在密集数组中的索引位置,然后写入稀疏数组,所谓稀疏数组仍旧是一个hashtable。 在写入时,对key进行hash,采用开放寻址法定位存储位置,根据我自己的理解和判断,在稀疏数组中,需要保存key和这个key在密集数组中的索引位置。
查找某个key时,先到稀疏数组中查找,得到在密集数组中的索引位置,而后根据索引位置从密集数组中获取到value。

扫描关注, 与我技术互动
QQ交流群: 211426309
